An advent calendar about the Java programming language, posting an interesting technical article from various authors related to Java daily between the 1st and 24th of December, each year.
We're gearing up for an other great Java advent season. Feel free to browse the archives for 2014, 2013 and 2012. Also, make sure to subscribe by one of the following ways to make sure that you don't miss a single post:
This is the first year of the Java Advent Project and I am really grateful to all the people that got involved, published articles, twitted, shared, +1ed, shared etc. etc.
It was an unbelievable journey and all the glory needs to go to the people that took some time from their loved ones to give us their wisdom. As they say, the Class of 2014 of Java Advent is comprised of (in the order of publishing date):
Thank you girls and guys for making it happen yet once more. And sorry for stressing and pushing you out. Also, last but not least thanks to Voxxed editors Lucy Carey and Mite Mitreski.
What could be more fitting than Christmas music for Christmas Eve?
In this post I want to discuss the joy of making music with Java and why/how I have come to use Python...
But first, let us celebrate the season!
We are all human and irrespective of our beliefs, it seems we all enjoy music of some form. For me some of the most beautiful music of all was written by Johan Sebastian Bach. Between 1708 and 1717 he wrote a set of pieces which are collectively called Orgelbüchlein (Little Organ Book). For this post and to celebrate the Java Advent Calendar I tasked Sonic Field to play this piece of music modelling the sounds of a 18th century pipe organ. If you did not know, yes some German organs of about that time really were able to produce huge sounds with reed pipes (for example, Passacaglia And Fugue the Trost Organ). The piece here is a 'Choral Prelude' which is based on what we would in English commonly call a Carol to be sung by an ensemble.
BWV 610 Jesu, meine Freude [Jesus, my joy] This performance dedicated to the Java Advent Calendar and created exclusively on the JVM using pure mathematics.
How was this piece created?
Step one is to transcribe the score into midi. Fortunately, someone else already did this for me using automated score reading software. Not so fortunately, this software makes all sorts of mistakes which have to be fixed. The biggest issue with automatically generated midi files is that they end up with overlapped notes on the same channel; that is strictly impossible in midi and ends up with an ambiguous interpretation of what the sound should be. Midi considers audio as note on, note off. So Note On, Note On, Note Off, Note Off is ambiguous; does it mean:
One note overlapping the next or: ----------------- ---------------
One note entirely contained in a longer note? ---------------------------- ----
Fortunately, tricks can be used to try and figure this out based on note length etc. The Java decoder always treats notes as fully contained. The Python method looks for very short notes which are contained in long ones and guesses the real intention was two long notes which ended up overlapped slightly. Here is the python (the Java is here on github).
def repareOverlapMidi(midi,blip=5):
print "Interpretation Pass"
mute=True
while mute:
endAt=len(midi)-1
mute=False
index=0
midiOut=[]
this=[]
next=[]
print "Demerge pass:",endAt
midi=sorted(midi, key=lambda tup: tup[0])
midi=sorted(midi, key=lambda tup: tup[3])
while index<endAt:
this=midi[index]
next=midi[index+1]
ttickOn,ttickOff,tnote,tkey,tvelocity=this
ntickOn,ntickOff,nnote,nkey,nvelocity=next
# Merge interpretation
finished=False
dif=(ttickOff-ttickOn)
if dif<blip and tkey==nkey and ttickOff>=ntickOn and ttickOff<=ntickOff:
print "Separating: ",this,next," Diff: ",(ttickOff-ntickOn)
midiOut.append([ttickOn ,ntickOn ,tnote,tkey,tvelocity])
midiOut.append([ttickOff,ntickOff,nnote,nkey,nvelocity])
index+=1
mute=True
elif dif<blip:
print "Removing blip: ",(ttickOff-ttickOn)
index+=1
mute=True
continue
else:
midiOut.append(this)
# iterate the loop
index+=1
if index==endAt:
midiOut.append(next)
if not mute:
return midiOut
midi=midiOut
Then comes some real fun. If you know the original piece, you might have noticed that the introduction is not original. I added that in the midi editing software Aria Maestosa. It does not need to be done this way; we do not even need to use midi files. A lot of the music I have created in Sonic Field is just coded directly in Python. However, from midi is how it was done here.
Once we have a clean set of notes they need to be converted into sounds. That is done with 'voicing'. I will talk a little about that to set the scene then we can get back into more Java code oriented discussion. After all, this is the Java advent calendar!
Voicing is exactly the sort of activity which brings Python to the fore. Java is a wordy language which has a large degree of strictness. It favours well constructed, stable structures. Python relies on its clean syntax rules and layout and the principle of least astonishment. For me, this Pythonic approach really helps with the very human process of making a sound:
Above is a 'voice'. Contrary to what one might think, a synthesised sound does not often consist of just one sound source. It consists of many. A piece of music might have many 'voices' and each voice will be a composite of several sounds. To create just the one voice above I have split the notes into long notes and short notes. Then the actual notes are created by a call to doMidi. This takes advantage of Python's 'named arguments with default values' feature. Here is the signature for doMidi:
The most complex (unsurprisingly) voice to create is that of a human singing. I have been working on this for a long time and there is a long way to go; however, its is a spectrogram of a piece of music which does a passable job of sounding like someone singing.
The first argument is actually a reference to a function which will create the basic tone. The rest of the arguments describe how that tone will be manipulated in the note formation. Whilst an approach like this can be mimicked using a builder pattern in Java; this latter language does not lend it self to the 'playing around' nature of Python (at least for me).
For example, I could just run the script and add flatEvn=True to the arguments and run it again and compare the two sounds. It is an intuitive way of working.
Anyhow, once each voice has been composited from many tones and tweaked into the shape and texture we want, they turn up as a huge list of lists of notes which are all mixed together and written out to disk as a flat file format which is basically just a dump of the underlying double data. At this point it sounds terrible! Making the notes is often only half the story.
Voice Synthesis by Sonic Field
played specifically for this post.
You see, real sounds happen in a space. Our Choral is expected to be performed in a church. Notes played without a space around them sound completely artificial and lack any interest. To solve this we use impulse response reverberation. The mathematics behind this is rather complex and so I will not go into it in detail. However in the next section I will start to look at this as a perfect example of why Java is not only necessary but ideal as the back end to Python/Jython.
You seem to like Python Alex - Why Bother With Java?
My post might seem a bit like a Python sales job so far. What has been happening is simply a justification of using Python when Java is so good as a language (especially when written in a great IDE like Eclipse for Java). Let us look at something Python would be very bad indeed at. Here is the code for performing the Fast Fourier Transform, which is a the heart of putting sounds into a space.
package com.nerdscentral.audio.pitch.algorithm;
public class CacheableFFT
{
private final int n, m;
// Lookup tables. Only need to recompute when size of FFT changes.
private final double[] cos;
private final double[] sin;
private final boolean forward;
public boolean isForward()
{
return forward;
}
public int size()
{
return n;
}
public CacheableFFT(int n1, boolean isForward)
{
this.forward = isForward;
this.n = n1;
this.m = (int) (Math.log(n1) / Math.log(2));
// Make sure n is a power of 2
if (n1 != (1 << m)) throw new RuntimeException(Messages.getString("CacheableFFT.0")); //$NON-NLS-1$
cos = new double[n1 / 2];
sin = new double[n1 / 2];
double dir = isForward ? -2 * Math.PI : 2 * Math.PI;
for (int i = 0; i < n1 / 2; i++)
{
cos[i] = Math.cos(dir * i / n1);
sin[i] = Math.sin(dir * i / n1);
}
}
public void fft(double[] x, double[] y)
{
int i, j, k, n1, n2, a;
double c, s, t1, t2;
// Bit-reverse
j = 0;
n2 = n / 2;
for (i = 1; i < n - 1; i++)
{
n1 = n2;
while (j >= n1)
{
j = j - n1;
n1 = n1 / 2;
}
j = j + n1;
if (i < j)
{
t1 = x[i];
x[i] = x[j];
x[j] = t1;
t1 = y[i];
y[i] = y[j];
y[j] = t1;
}
}
// FFT
n1 = 0;
n2 = 1;
for (i = 0; i < m; i++)
{
n1 = n2;
n2 = n2 + n2;
a = 0;
for (j = 0; j < n1; j++)
{
c = cos[a];
s = sin[a];
a += 1 << (m - i - 1);
for (k = j; k < n; k = k + n2)
{
t1 = c * x[k + n1] - s * y[k + n1];
t2 = s * x[k + n1] + c * y[k + n1];
x[k + n1] = x[k] - t1;
y[k + n1] = y[k] - t2;
x[k] = x[k] + t1;
y[k] = y[k] + t2;
}
}
}
}
}
It would be complete lunacy to implement this methematics in JPython (dynamic late binding would give unusably bad performance). Java does a great job of running it quickly and efficiently. In Java this runs just about as fast as it could in any language plus the clean, simple object structure of Java means that using the 'caching' system as straight forward. The caching comes from the fact that the cos and sin multipliers of the FFT can be re-used when the transform is the same length. Now, in the creation of reverberation effects (those effects which put sound into a space) FFT lengths are the same over and over again due to windowing. So the speed and object oriented power of Java have both fed into creating a clean, high performance implementation.
But we can go further and make the FFT parallelised:
def reverbInner(signal,convol,grainLength):
def rii():
mag=sf.Magnitude(+signal)
if mag>0:
signal_=sf.Concatenate(signal,sf.Silence(grainLength))
signal_=sf.FrequencyDomain(signal_)
signal_=sf.CrossMultiply(convol,signal_)
signal_=sf.TimeDomain(signal_)
newMag=sf.Magnitude(+signal_)
if newMag>0:
signal_=sf.NumericVolume(signal_,mag/newMag)
# tail out clicks due to amplitude at end of signal
return sf.Realise(signal_)
else:
return sf.Silence(sf.Length(signal_))
else:
-convol
return signal
return sf_do(rii)
def reverberate(signal,convol):
def revi():
grainLength = sf.Length(+convol)
convol_=sf.FrequencyDomain(sf.Concatenate(convol,sf.Silence(grainLength)))
signal_=sf.Concatenate(signal,sf.Silence(grainLength))
out=[]
for grain in sf.Granulate(signal_,grainLength):
(signal_i,at)=grain
out.append((reverbInner(signal_i,+convol_,grainLength),at))
-convol_
return sf.Clean(sf.FixSize(sf.MixAt(out)))
return sf_do(revi)
Here we have the Python which performs the FFT to produce impulse response reverberation (convolution reverb is another name for this approach). The second function breaks the sound into grains. Each grain is then processes individually and they all have the same length. This performs that windowing effect I talked about earlier (I use a triangular window which is not ideal but works well enough due to the long window size). If the grains are long enough, the impact of lots of little FFT calculation basically the same as the effect of one huge one. However, FFT is a nLog(n) process, so lots of little calculations is a lot faster than one big one. In effect, windowing make FFT become a linear scaling calculation.
Note that the granulation process is performed in a future. We define a closure called revi and pass it to sf_do() which is executed it at some point in the future base on demand and the number of threads available. Next we can look at the code which performs the FFT on each grain - rii. That again is performed in a future. In other words, the individual windowed FFT calculations are all performed in futures. The expression of a parallel windowed FFT engine in C or FORTRAN ends up very complex and rather intractable. I have not personally come across one which is integrated into the generalised, thread pooled, future based schedular. Nevertheless, the combination of Jython and Java makes such a thing very easy to create.
How are the two meshed?
Now that I hope I have put a good argument for hybrid programming between a great dynamic language (in this case Python) and a powerful mid level static language (in this case Java) it is time to look at how the two are fused together. There are many ways of doing this but Sonic Field picks a very distinct approach. It does not offer a general interface between the two where lots of intermediate code is generated and each method in Java is exposed separately into Python; rather it uses a uniform single interface with virtual dispatch.
Sonic Field defines a very (aggressively) simple calling convention from Python into Java which initially might look like a major pain in the behind but works out to create a very flexible and powerful approach.
Sonic Field defines 'operators' which all implement the following interface:
/* For Copyright and License see LICENSE.txt and COPYING.txt in the root directory */
package com.nerdscentral.sython;
import java.io.Serializable;
/**
* @author AlexTu
*
*/
public interface SFPL_Operator extends Serializable
{
/**
* <b>Gives the key word which the parser will use for this operator</b>
*
* @return the key word
*/
public String Word();
/**
* <b>Operate</b> What ever this operator does when SFPL is running is done by this method. The execution loop all this
* method with the current execution context and the passed forward operand.
*
* @param input
* the operand passed into this operator
* @param context
* the current execution context
* @return the operand passed forward from this operator
* @throws SFPL_RuntimeException
*/
public Object Interpret(Object input, SFPL_Context context) throws SFPL_RuntimeException;
}
The word() method returns the name of the operator as it will be expressed in Python. The Interpret() method processes arguments passed to it from Python. As Sonic Field comes up it creates a Jython interpreter and then adds the operators to it. The mechanism for doing this is a little involved so rather than go into detail here, I will simply give links to the code on github:
The result is that every operator is exposed in Python as sf.xxx where xxx is the return from the word() method. With clever operator overloading and other syntactical tricks in Python I am sure that the approach could be refined. Right now, there are a lot of sf.xxx calls in Sonic Field Python ( I call it Synthon ) but I have not gotten around to improving on this simple and effective approach.
You might have noticed that everything passed into Java from Python is just 'object'. This seems a bit crude at first take. However, as we touched on in the section of futures in the previous post, it offers many advantages because the translation from Jython to Java is orchestrated via the Caster object and a layer of Python which transparently perform many useful translations. For example, the code automatically translates multiple arguments in Jython to a list of objects in Java:
def run(self,word,input,args):
if len(args)!=0:
args=list(args)
args.insert(0,input)
input=args
trace=''.join(traceback.format_stack())
SFSignal.setPythonStack(trace)
ret=self.processors.get(word).Interpret(input,self.context)
return ret
Here we can see how the arguments are processed into a list (which is Jython is implemented as an ArrayList) if there are more than one but are passed as a single object is there is only one. We can also see how the Python stack trace is passed into a thread local in the Java SFSignal object. Should an SFSignal not be freed or be double collected, this Python stack is displayed to help debug the program.
Is this interface approach a generally good idea for Jython/Java Communication?
Definitely not! It works here because of the nature of the Sonic Field audio progressing architecture. We have processors which can be chained. Each processor has a simple input and output. The semantic content passed between Python and Java is quite limited. In more general purpose programming, this simple architecture, rather than being flexible and powerful, would be highly restrictive. In this case, the normal Jython interface with Java would be much more effective. Again, we can see a great example of this simplicity in the previous post when talking about threading (where Python access Java Future objects). Another example is the direct interaction of Python with SFData objects in this post on modelling oscillators in Python.
from com.nerdscentral.audio import SFData
...
data=SFData.build(len)
for x in range(0,length):
s,t,xs=osc.next()
data.setSample(x,s)
Which violated the programming model of Sonic Field by creating audio samples directly from Jython, but at the same time illustrates the power of Jython! It also created one of the most unusual soundscapes I have so far achieved with the technology:
Engines of war, sound modelling
from oscillators in Python.
Wrapping It Up
Well, that is all folks. I could ramble on for ever, but I think I have answered most if not all of the questions I set out in the first post. The key ones that really interest me are about creativity and hybrid programming. Naturally, I am obsessed with performance as I am by profession an optimisation consultant, but moving away from my day job, can Jython and Java be a creating environment and do they offer more creativity than pure Java?
Transition State Analysis using
hybrid programming
Too many years ago I worked on a similar hybrid approach in scientific computing. The GRACE software which I helped develop as part of the team at Bath was able to break new ground because it was easier to explore ideas in the hybrid approach than writing raw FORTRAN constantly. I cannot present in deterministic, reductionist language a consistent argument for why this applied then to science or now to music; nevertheless, experience from myself and others has show this to be a strong argument.
Whether you agree or disagree; irrespective of if you like the music or detest it; I wish you a very merry Christmas indeed.
1. February the 1st - RedMonk Analyst firm declares that Java is more popular & diverse than ever!
The Java Ecosystem started off with a hiss and a roar in 2014 with the annual meeting of the Free Java room at FOSDEM. As well as the many fine deep technical talks on OpenJDK and related topics there was also a surprise presentation on the industry from
Steve O'Grady (RedMonk Analyst). Steve gave a data lead insight into where Java ranked in terms of both popularity and scope at the start of 2014. The analysis on where Java is as a language is repeated on RedMonk's Blog. The fact it remains a top two language didn't surprise anyone, but it was the other angle that really surprised even those of us heavily involved in the ecosystem. Steve's talk clearly showed that Java is aggressively diverse, appearing in industries such as social media, messaging, gaming, mobile, virtualisation, build systems and many more, not just Enterprise apps that people most commonly think about. Steve also showed that Java is being used heavily in new projects (across all of those industry sectors) which certainly killed the myth of Java being a legacy enterprise platform.
2. March the 18th - Java 8 arrives
The arrival of Java 8 ushered in a new Functional/OO hybrid direction for the language giving it a new lease of life. The adoption rates have been incredible (See Typesafe's full report on this) it was clearly the release that Java developers were waiting for.
Some extra thoughts around the highlights of this release:
Lambdas (JSR 335) - There has been so much written about this topic already with a ton of fantastic books and tutorials to boot. For me the clear benefit to most Java developers was that they're finally able to express the correct intent of behaviour with collections without all of the unnecessary boiler plate that imperative/OO constructs forced upon them. It boils down to the old adage of That there are only two problems in computer science, cache invalidation, naming things, and off-by-one errors. The new streams API for collection in conjunction with Lambdas certainly helps with the last two!
Project Nashorn (JSR 223, JEP 174) - The JavaScript runtime which allows developers to embed JavaScript code within their Java applications. Although I personally won't be using this anytime soon, it was yet another boost to the JVM in terms of first class support for dynamically typed languages. I'm looking forward to this trend continuing!
Date and Time API (JSR 310, JEP 150) - This is sort of bread and butter API that a blue collar language like Java just needs to get right, and this time (take 3) they did! It's been great to finally be able to work with timezones correctly and it also set a new precedence of Immutable First as a conscious design decision for new APIs in Java.
3. ~July - ARM 64 port (AArch64)
RedHat have lead the effort to get the ARMv8 64-bit architecture supported in Java. This is clearly an important step to keep Java truly "Run anywhere" and alongside SAP's PowerPC/AIX port represents two major ports that are primarily maintained by non-Oracle participants in OpenJDK. If you'd like to help get involved see the project page for more details.
Java still has a way to go before becoming a major player in the embedded space, but the signs in 2014 were encouraging with Java SE Embedded featuring regularly on the Raspberry Pi and Java ME Embedded getting a much needed feature parity boost with Java SE APIs.
4. Sept/Oct - A Resurgence in the JCP & it's 15th Anniversary
The Java Community Process (JCP) is the standards body that defines what goes into Java SE, Java EE and the Java ME. It re-invented itself as a much more open community based organisation in 2013 and continued that good work in 2014, reversing the dropping membership trend. Most importantly - it now truly represents the incredible diversity that the Java ecosystem has. You can see the make up of the existing Executive Committee - you can see that institutions like Java User Groups sitting alongside industry and end user heavyweights such as IBM, Twitter and Goldman Sachs.
Community Collaboration at an all time high & Microsoft joins OpenJDK.
The number of new joiners to OpenJDK (see Mani's excellent post on this) was higher than ever. OpenJDK now represents a huge melting pot of major tech companies such as Red Hat, IBM, Oracle, Twitter and of course the shock entry this year of Microsoft.
The Adopt a JSR and Adopt OpenJDK programmes continue to bring more day to day developers involved in guiding the future of various APIs with regular workshops now being organised globally around the world to test new APis and ideas out early and feed that back in OpenJDK and the Java EE specifications in particular.
Community conferences & the number of Java User Groups continue rise in numbers, JavaOne in particular having it's strongest year in recent memory. It was also heartening to see a large number of community efforts helping kids learn to code with after school and weekend programmes such as Devoxx for Kids.
What for 2015?
I'll expect 2015 to be a little bit quieter in terms of changes for the core language or exciting new features to Java EE or Java ME as their next major releases aren't due to 2016. On the community etc front I expect to see Java developers having to firmly embrace web/UI technologies such as AngularJS, More systems/Devops toolchains such as Docker, AWS, Puppet etc and of course migrate to Java 8 and all of the functional goodness it now brings!
The community I'm sure will continue to thrive and the looming spectre of IoT will start to come into the mainstream as well. Java developers will likely have to wait until Java 9 to get a truly first class platform for embedded, but early adopters will want to begin taking a look at early builds throughout 2015.
Java/JVM applications now tend to be complex, with many moving parts and distributed deployments. It can often take poor frustrated developers weeks to fix issues in production. To combat this there are a new wave of interesting analysis tools dealing with Java/JVM based applications and deployments. Oracle's Mission Control is a powerful tool that can give lots of interesting insights into the JVM and other tools like Xrebel from ZeroTurnaround, jClarity's Censum and Illuminate take the next step of applying machine learned analysis to the raw numbers.
One final important note. Project Jigsaw is the modularisation story for Java 9 that will massively impact tool vendors and day to day developers alike. The community at large needs your help to help test out early builds of Java 9 and to help OpenJDK developers and tool vendors ensure that IDEs, build tools and applications are ready for this important change. You can join us in the Adoption Group at OpenJDK:
http://adoptopenjdk.java.net
I hope everyone has a great holiday break - I look forward to seeing the Twitter feeds and the GitHub commits flying around in 2015 :-).
Cheers,
Martijn (CEO - jClarity, Java Champion & Diabolical Developer)
Advent time again .. picking up Peters well written overview on the uses of Unsafe, i'll have a short fly-by on how low level techniques in Java can save development effort by enabling a higher level of abstraction or allow for Java performance levels probably unknown to many.
My major point is to show that conversion of Objects to bytes and vice versa is an important fundamental, affecting virtually any modern java application.
Hardware enjoys to process streams of bytes, not object graphs connected by pointers as "All memory is tape"(M.Thompson if I remember correctly ..).
Many basic technologies are therefore hard to use with vanilla Java heap objects:
Memory Mapped Files - a great and simple technology to persist application data safe, fast & easy.
Network communication is based on sending packets of bytes
Interprocess communication (shared memory)
Large main memory of today's servers (64GB to 256GB). (GC issues)
CPU caches work best on data stored as a continuous stream of bytes in memory
so use of the Unsafe class in most cases boil down in helping to transform a java object graph into a continuous memory region and vice versa either using
[performance enhanced] object serialization or
wrapper classes to ease access to data stored in a continuous memory region.
(source of examples used in this post can be found here, messaginglatency test here)
Serialization based Off-Heap
Consider a retail WebApplication where there might be millions of registered users. We are actually not interested in representing data in a relational database as all needed is a quick retrieve of user related data once he logs in. Additionally one would like to traverse the social graph quickly.
Let's take a simple user class holding some attributes and a list of 'friends' making up a social graph.
easiest way to store this on heap, is a simple huge HashMap.
Alternatively one can use off heap maps to store large amounts of data. An off heap map stores its keys and values inside the native heap, so garbage collection does not need to track this memory. In addition, native heap can be told to automagically get synchronized to disk (memory mapped files). This even works in case your application crashes, as the OS manages write back of changed memory regions.
There are some open source off heap map implementations out there with various feature sets (e.g. ChronicleMap), for this example I'll use a plain and simple implementation featuring fast iteration (optional full scan search) and ease of use.
Serialization is used to store objects, deserialization is used in order to pull them to the java heap again. Pleasantly I have written the (afaik) fastest fully JDK compliant object serialization on the planet, so I'll make use of that.
Done:
persistence by memory mapping a file (map will reload upon creation).
Java Heap still empty to serve real application processing with Full GC < 100ms.
Significantly less overall memory consumption. A user record serialized is ~60 bytes, so in theory 300 million records fit into 180GB of server memory. No need to raise the big data flag and run 4096 hadoop nodes on AWS ;).
Comparing a regular in-memory java HashMap and a fast-serialization based persistent off heap map holding 15 millions user records, will show following results (on a 3Ghz older XEON 2x6):
As one can see, even with fast serialization there is a heavy penalty (~factor 5) in access performance, anyway: compared to other persistence alternatives, its still superior (1-3 microseconds per "get" operation, "put()" very similar).
Use of JDK serialization would perform at least 5 to 10 times slower (direct comparison below) and therefore render this approach useless.
Trading performance gains against higher level of abstraction: "Serverize me"
A single server won't be able to serve (hundreds of) thousands of users, so we somehow need to share data amongst processes, even better: across machines.
Using a fast implementation, its possible to generously use (fast-) serialization for over-the-network messaging. Again: if this would run like 5 to 10 times slower, it just wouldn't be viable. Alternative approaches require an order of magnitude more work to achieve similar results.
By wrapping the persistent off heap hash map by an Actor implementation (async ftw!), some lines of code make up a persistent KeyValue server with a TCP-based and a HTTP interface (uses kontraktor actors). Of course the Actor can still be used in-process if one decides so later on.
Now that's a micro service. Given it lacks any attempt of optimization and is single threaded, its reasonably fast [same XEON machine as above]:
280_000 successful remote lookups per second
800_000 in case of fail lookups (key not found)
serialization based TCP interface (1 liner)
a stringy webservice for the REST-of-us (1 liner).
A real world implementation might want to double performance by directly putting received serialized object byte[] into the map instead of encoding it twice (encode/decode once for transmission over wire, then decode/encode for offheaping map).
"RestActorServer.Publish(..);" is a one liner to also expose the KVActor as a webservice in addition to raw tcp:
C like performance using flyweight wrappers / structs With serialization, regular Java Objects are transformed to a byte sequence. One can do the opposite: Create wrapper classes which read data from fixed or computed positions of an underlying byte array or native memory address. (E.g. see this blog post).
By moving the base pointer its possible to access different records by just moving the the wrapper's offset. Copying such a "packed object" boils down to a memory copy. In addition, its pretty easy to write allocation free code this way. One downside is, that reading/writing single fields has a performance penalty compared to regular Java Objects. This can be made up for by using the Unsafe class.
"flyweight" wrapper classes can be implemented manually as shown in the blog post cited, however as code grows this starts getting unmaintainable.
Fast-serializaton provides a byproduct "struct emulation" supporting creation of flyweight wrapper classes from regular Java classes at runtime. Low level byte fiddling in application code can be avoided for the most part this way.
How a regular Java class can be mapped to flat memory (fst-structs):
Of course there are simpler tools out there to help reduce manual programming of encoding (e.g. Slab) which might be more appropriate for many cases and use less "magic".
What kind of performance can be expected using the different approaches (sad fact incoming) ?
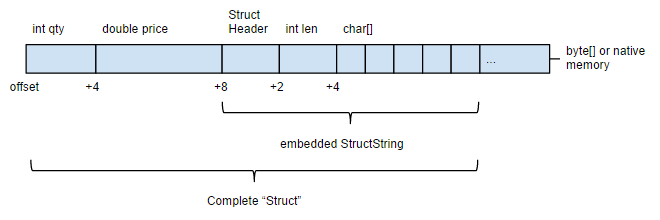
Lets take the following struct-class consisting of a price update and an embedded struct denoting a tradable instrument (e.g. stock) and encode it using various methods:
a 'struct' in code
Pure encoding performance:
Structs
fast-Ser (no shared refs)
fast-Ser
JDK Ser (no shared)
JDK Ser
26.315.000,00
7.757.000,00
5.102.000,00
649.000,00
644.000,00
Real world test with messaging throughput:
In order to get a basic estimation of differences in a real application, i do an experiment how different encodings perform when used to send and receive messages at a high rate via reliable UDP messaging:
The Test: A sender encodes messages as fast as possible and publishes them using reliable multicast, a subscriber receives and decodes them.
Structs
fast-Ser (no shared refs)
fast-Ser
JDK Ser (no shared)
JDK Ser
6.644.107,00
4.385.118,00
3.615.584,00
81.582,00
79.073,00
(Tests done on I7/Win8, XEON/Linux scores slightly higher, msg size ~70 bytes for structs, ~60 bytes serialization).
Slowest compared to fastest: factor of 82. The test highlights an issue not covered by micro-benchmarking: Encoding and Decoding should perform similar, as factual throughput is determined by Min(Encoding performance, Decoding performance). For unknown reasons JDK serialization manages to encode the message tested like 500_000 times per second, decoding performance is only 80_000 per second so in the test the receiver gets dropped quickly: " ... ***** Stats for receive rate: 80351 per second ********* ***** Stats for receive rate: 78769 per second ********* SUB-ud4q has been dropped by PUB-9afs on service 1 fatal, could not keep up. exiting "
(Creating backpressure here probably isn't the right way to address the issue ;-) )
Conclusion:
a fast serialization allows for a level of abstraction in distributed applications impossible if serialization implementation is either - too slow - incomplete. E.g. cannot handle any serializable object graph - requires manual coding/adaptions. (would put many restrictions on actor message types, Futures, Spore's, Maintenance nightmare)
Low Level utilities like Unsafe enable different representations of data resulting in extraordinary throughput or guaranteed latency boundaries (allocation free main path) for particular workloads. These are impossible to achieve by a large margin with JDK's public tool set.
In distributed systems, communication performance is of fundamental importance. Removing Unsafe is not the biggest fish to fry looking at the numbers above .. JSON or XML won't fix this ;-).
While the HotSpot VM has reached an extraordinary level of performance and reliability, CPU is wasted in some parts of the JDK like there's no tomorrow. Given we are living in the age of distributed applications and data, moving stuff over the wire should be easy to achieve (not manually coded) and as fast as possible.
Addendum: bounded latency
A quick Ping Pong RTT latency benchmark showing that java can compete with C solutions easily, as long the main path is allocation free and techniques like described above are employed:
[credits: charts+measurement done with HdrHistogram]
This is an "experiment" rather than a benchmark (so do not read: 'Proven: Java faster than C'), it shows low-level-Java can compete with C in at least this low-level domain.
Of course its not exactly idiomatic Java code, however its still easier to handle, port and maintain compared to a JNI or pure C(++) solution. Low latency C(++) code won't be that idiomatic either ;-)
We've been working at 4financeit for last couple of months on some open source solutions for microservices. I will be publishing some articles related to microservices and our tools and this is the first of (hopefully) many that I will write in the upcoming weeks (months?) on Too much coding blog.
This article will be an introduction to the micro-infra-spring library showing how you can quickly set up a microservice using our tools.
















{kind=link}